Published in IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
Abstract
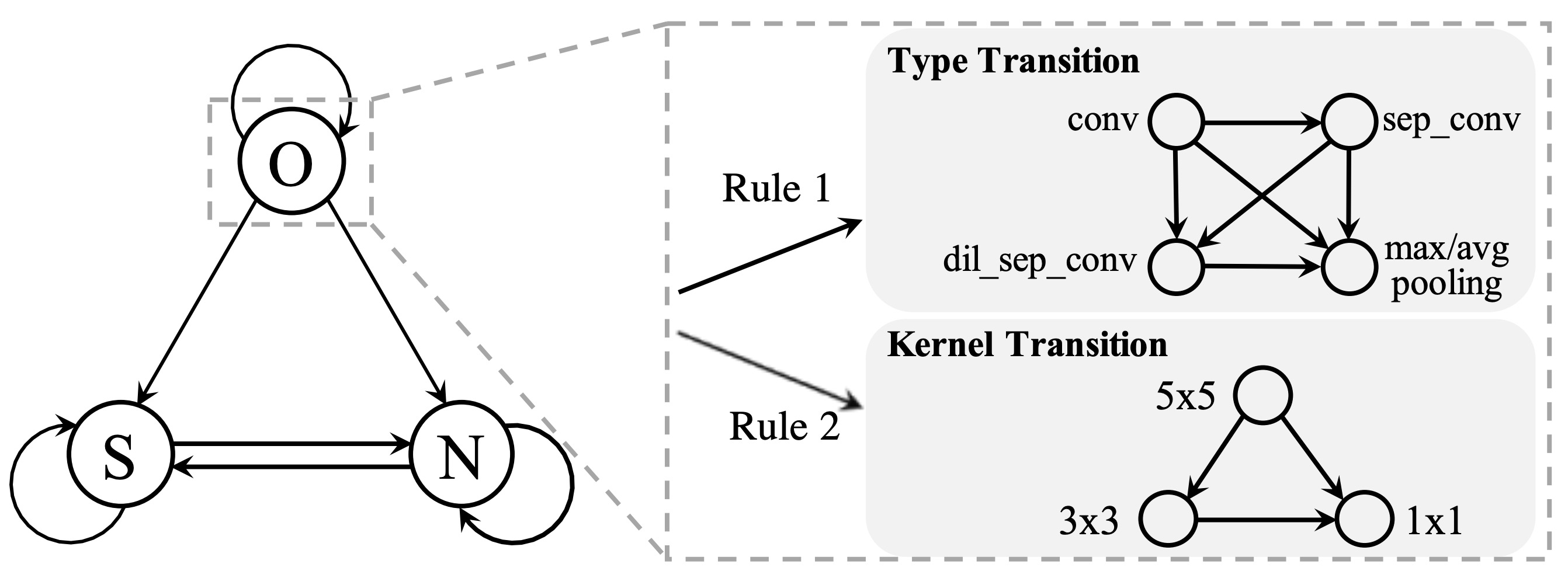
Designing effective architectures is one of the key factors behind the success of deep neural networks. Existing deep architectures are either manually designed or automatically searched by some Neural Architecture Search (NAS) methods. However, even a well-designed/searched architecture may still contain many nonsignificant or redundant modules/operations (e.g., some intermediate convolution or pooling layers). Such redundancy may not only incur substantial memory consumption and computational cost but also deteriorate the performance. Thus, it is necessary to optimize the operations inside an architecture to improve the performance without introducing extra computational cost. To this end, we have proposed a Neural Architecture Transformer (NAT) method which casts the optimization problem into a Markov Decision Process (MDP) and seeks to replace the redundant operations with more efficient operations, such as skip or null connection. Note that NAT only considers a small number of possible transitions and thus comes with a limited search/transition space. As a result, such a small search space may hamper the performance of architecture optimization. To address this issue, we propose a Neural Architecture Transformer++ (NAT++) method which further enlarges the set of candidate transitions to improve the performance of architecture optimization. Specifically, we present a two-level transition rule to obtain valid transitions, i.e., allowing operations to have more efficient types (e.g., convolution→separable convolution) or smaller kernel sizes (e.g., 5×5→3×3). Note that different operations may have different valid transitions. We further propose a Binary-Masked Softmax (BMSoftmax) layer to omit the possible invalid transitions. Last, based on the MDP formulation of NAT and NAT++, we apply policy gradient to learn an optimal policy, which will be used to infer the optimized architectures. We apply NAT and NAT++ to optimize both hand-crafted architectures and NAS based architectures. Extensive experiments on several benchmark datasets show that the transformed architecture significantly outperforms both its original counterpart and the architectures optimized by existing methods.